Сводки, группировки и ряды распределения статистических данных

Изучаемая статистическая совокупность разбивается на группировки, имеющие общие черты и сходные размеры изучаемого признака. Результаты группировок записываются в виде группировочных таблиц. Таблица имеет три заголовка: общий, отражающий содержание всей таблицы с указанием места и времени, верхний, характеризующий содержание граф (заголовки сказуемого), и боковые, показывающие содержание строк… Читать ещё >
Сводки, группировки и ряды распределения статистических данных (реферат, курсовая, диплом, контрольная)
Рассмотрим второй этап статистического наблюдения — систематизацию первичных данных. Информация, полученная в ходе статистического наблюдения, не позволяет ни охарактеризовать, ни выявить закономерности социальных явлений. Эти данные характеризуют каждую единицу исследуемого объекта и не являются обобщающими показателями. Для получения сводной характеристики изучаемого объекта используется сводка, которая выражается в последовательности действий: проверка исходных данных; группировка данных по заданным признакам; вычисление производных показателей; оформление результатов в виде статистических таблиц.
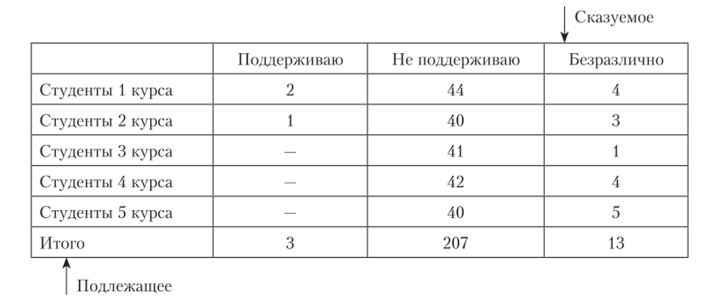
Изучаемая статистическая совокупность разбивается на группировки, имеющие общие черты и сходные размеры изучаемого признака. Результаты группировок записываются в виде группировочных таблиц. Таблица имеет три заголовка: общий, отражающий содержание всей таблицы с указанием места и времени, верхний, характеризующий содержание граф (заголовки сказуемого), и боковые, показывающие содержание строк (заголовки подлежащего). Подлежащим статистической таблицы выступает объект, характеризующийся цифрами. Сказуемым является система показателей, характеризующая объект или подлежащее. Ниже приведен пример груипировочной таблицы (табл. 2.1).
Отношение студентов факультета социологии к понижению размера стипендии в хххх г. (данные условные).
В зависимости от числа группировочных признаков группировки делятся на простые (один признак) и сложные (несколько признаков). Встречаются комбинированные группировки (разбивка каждой группы на подгруппы). С помощью специальных алгоритмов можно построить многомерные группировки: это значит — найти область скопления точек в iV-мерном пространстве.
Различают типологические группировки, которые выявляют качественно однородные группы в разнородной совокупности (например, группировка предприятий по формам собственности): структурные группировки, где однородная совокупность делится на группы по какому-либо варьирующему признаку, выявляющему ее структуру (например, группировка населения по полу, возрасту); аналитические группировки, которые изучают и выявляют взаимосвязи между исследуемыми общественными явлениями и их признаками. Заметим, что аналитическая группировка имеет разбивку признаков на факторные и результативные, что позволяет выявить их взаимосвязь, например, возрастание значения факторного признака влечет за собой возрастание или убывание значения результативного признака. В аналитической группировке единицы группируются по факторному признаку, а выделенные группы характеризуются средними значениями результативного признака.
Если исходные данные группируются на базе результатов статистических наблюдений, то это первичные группировки, в противном случае результат объединения или расщепления первичной группировки дает нам вторичную группировку.
При построении группировки встает вопрос выбора числа групп, которое зависит от типа признака, положенного в основу группировки, объема совокупности и степени вариации признака. Если признак качественный, то количество групп соответствует числу уровней градации признака. В случае количественного признака все множество значений признака делится на интервалы. При этом имеет место группировка с равными и неравными интервалами, последней по мере возможности стараются избегать.
Число группировок с равными интервалами определяется формулой Стерджесса: 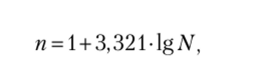
где п — число групп; N — число единиц совокупности.
В этом случае величина интервала определяется формулой.
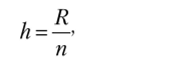
где R = хтах — xmin, размах вариации; хтах, хшш — максимальные и минимальные значения признака в совокупности.
Границы интервалов строятся по формулам.
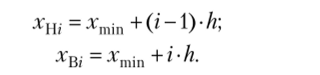
гдехН ( и хш — нижняя и верхняя границы соответственно.
Приближенное число интервалов п можно оценить исходя из объема совокупности N, используя выбор числа групп (табл. 2.2).
Число интервалов в зависимости от объема выборки.
Таблица 2.2
Объем выборки, N | Число интервалов, п |
25−40. | 5−6. |
40−60. | 6−8. |
60−100. | 7−10. |
100−200. | 8−12. |
Более 200. | 10−15. |
Пример 2.1.
Пользуясь формулой Стерджесса, определим число интервалов группировки сотрудников фирмы из 50 человек по уровню дохода, если минимальный доход составляет 2200 у.д.е. (условных денежных единиц), а максимальный доход — 5000 у.д.е. Для объема совокупности N= 50 число интервалов по таблице можно принять п = 7, что соответствует расчетам по формуле Стерджесса (п = 6,6).
Число интервалов выбрано, определим его длину по формуле.
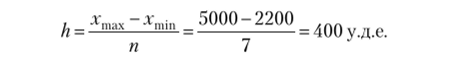
Обозначим границы групп: 2200—2600 — 1-я группа; 2600—3000 — 2-я группа; 3000—3400 — 3-я группа; 3400—3800 — 4-я группа; 3800—4200 — 5-я группа; 4200— 4600 — 6-я; 4600−5000 — 7-я.
Интервалы группировок могут быть открытыми и закрытыми. Закрытыми называются интервалы, у которых имеются верхняя и нижняя границы. У открытых интервалов указаны либо верхняя, либо нижняя границы.
Рассмотрим третий этап статистического исследования — построение рядов распределения.
Группировки производятся для того, чтобы построить эмпирическое распределение, с помощью которого можно будет выявить форму распределения изучаемого признака в статистической совокупности. Ряд распределения — это упорядоченное распределение единиц совокупности на группы по какому-либо признаку. Они бывают атрибутивными и вариационными. Атрибутивные ряды распределения составляются по атрибутивному (качественному) признаку, не имеющему количественной меры, например ряд распределения, составленный по признаку «социальное положение», «профессия», «пол»; вариационные ряды распределения строятся по количественному признаку.
Ряд распределения принято оформлять в виде таблицы. Пример атрибутивного ряда распределения приведен в табл. 2.3: на предприятии провели группировку работников по признаку «Категория».
Таблица 2.3
Распределение работников, но признаку «категория».
Категория. | Частота /,. | Частость Fjt % | cum fj | cum Fj |
Рабочие. | 58,3. | 58,3. | ||
Служащие. | 16,7. | |||
Инженерно-технические работники. | 12,5. | 87,5. | ||
Прочие. | 12,5. | |||
Итого. | ; | ; |
Частота (/,) — количество элементов совокупности, имеющее данное значение признака. Сумма всех частот равна численности всей совокупности. Накопленная частота (cum /;) интервала — это число, полученное последовательным суммированием частот в направлении от первого интервата к последнему до того интервала включительно, до которого определяется накопленная частота. Частость (F,) — отношение частоты к общему количеству исследуемых элементов, т. е. к объему совокупности. Сумма частостей равна единице, или 100%. Накопленной частостью называется отношение накопленной частоты к объему совокупности.
Вариационные ряды бывают дискретными и интервальными. Например, дискретный ряд представлен в табл. 2.4.
Таблица 2.4
Успеваемость студентов из 15 человек по одному из предметов.
Оценки. | Частота J) | Частость Fj, % |
13,3. | ||
26,7. |
Оценки. | Частота /. | Частость Fj, % |
33,3. | ||
26,7. | ||
Итого. |
Здесь значение признака принимает целые числа.
Удобно ряды распределения изображать графически в виде полигона или гистограммы, представляющих собой изменение частот.
Полигон строится для дискретных вариационных рядов. В прямоугольной системе координат по оси абсцисс в одинаковом масштабе откладываются ранжированные значения варьирующего признака, а по оси ординат — величины частот. Полученные на пересечении абсцисс и ординат точки соединяются прямыми линиями, в результате чего получается ломаная линия, которая называется полигоном частот. Изобразим графически распределение успеваемости студентов по одному из предметов (рис. 2.1).
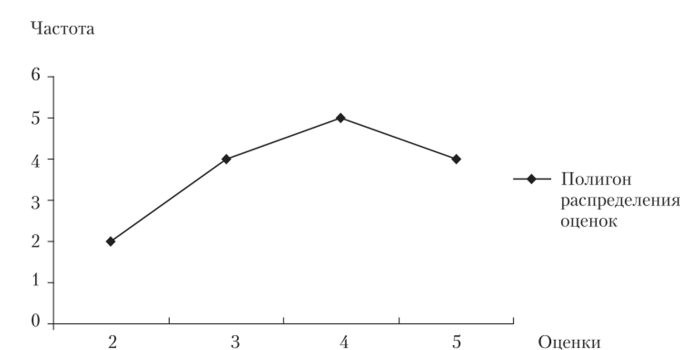
Рис. 2.1. Полигон распределения дискретного ряда.
Гистограмма применяется для изображения интервального ряда и представляет собой график, где ряд распределения изображен смежными столбиками. В прямоугольной системе координат на оси абсцисс откладываются величины интервалов, а частоты изображаются прямоугольными столбиками, построенными на соответствующих интервалах, высота столбика пропорциональна частотам.
Вернемся к примеру 2.1 и построим для него интервальный ряд, где в качестве основного показателя интервала используется его середина: х, — = = Х[ |( + h/2; результаты запишем в табл. 2.5.
Интервальный ряд распределения.
Номер интервала i | Заработная плата. | Частота /*. | cum/j. | Частость Fj, % | X,; |
2200−2600. | |||||
2600−3000. | |||||
3000−3400. | |||||
3400−3800. | |||||
3800−4200. | |||||
4200−4600. | |||||
4600−5000. | |||||
Итого. | ; | ; | ; |
Изобразим интервальный ряд графически (рис. 2.2).
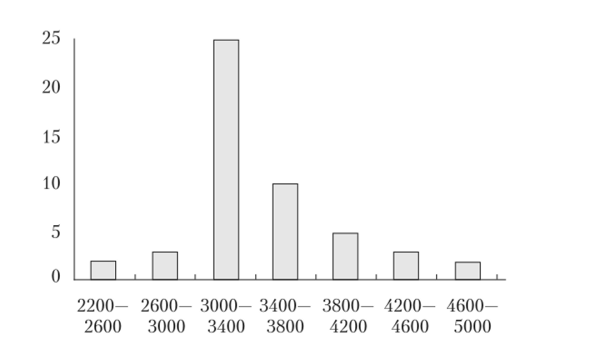
Рис. 2.2. Гистограмма распределения числа работников по размеру заработной платы.
Гистограмма преобразуется в полигон, если соединить середины сторон прямоугольников (рис. 2.3).
Для изображения вариационных рядов используется кумулятивная кривая, или кумулята, изображающая ряд накопленных частот (рис. 2.4). Накопленные частоты (cum /,) определяются путем последовательного суммирования частот по группам и показывают, сколько единиц совокупности имеют значение признака не больше, чем рассматриваемое значение. Построим кумуляту распределения числа работников по размеру заработной платы (см. табл. 2.5).
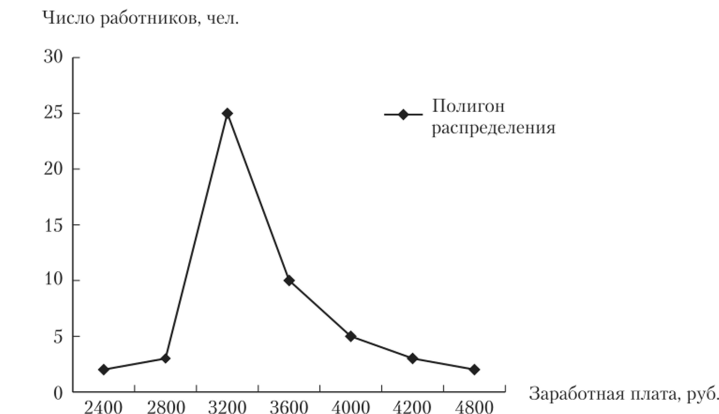
Рис. 23. Полигон распределения числа работников по размеру заработной платы.
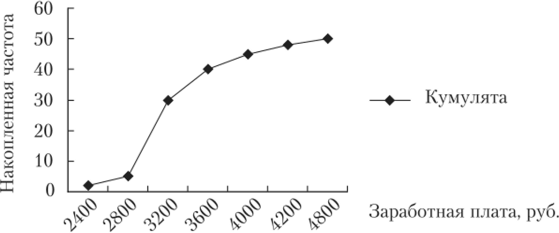
Рис. 2.4. Кумулята распределения числа работников по размеру заработной платы.
Если оси поменять местами, то получим кривую, которая называется огивой (рис. 2.5).
С помощью кумулятивных кривых изображается процесс концентрации, который представляет собой степень неравномерности распределения определенного суммарного показателя между единицами отдельных групп вариационного ряда. Эта кривая носит название кривой Лоренца, или кривой концентрации, на ее основе рассчитывается коэффициент Джини. График кривой изображается в прямоугольной системе координат, где зафиксирован квадрат 100×100. По оси х откладываются накопленные частоты объема совокупности, а по оси у — накопленные частоты признака.
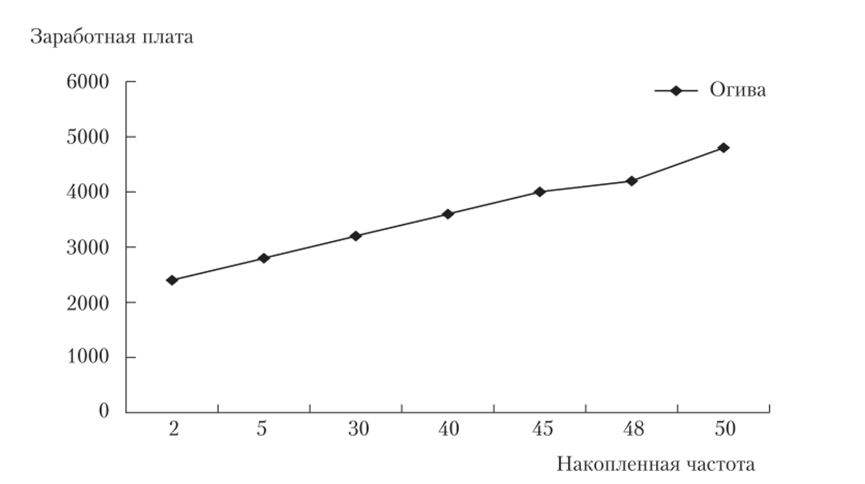
Рис. 25. Огива Построим кривую Лоренца по имеющимся данным в табл. 2.6.
Таблица 2.6
Распределение городов по числу жителей и распределение населения
в этих городах
Города с числом жителей, тыс. чел. | Число городов со, % к итогу. | Численность населения у-г % к итогу. | Кумулятивные итоги. | |
процент городов cum со,. | процент населения cum у{ | |||
ДоЗ. | 4,2. | 0,2. | 4,2. | 0,2. |
3−5. | 4,6. | 0,3. | 8,8. | 0,5. |
5−10. | 13,1. | 1,7. | 21,9. | 2,2. |
10−20. | 28,3. | 6,8. | 50,2. | 9,0. |
20−50. | 28,7. | 14,8. | 78,9. | 23,8. |
50−100. | 9,7. | 10,3. | 88,6. | 34,1. |
100 -500. | 9,7. | 33,8. | 98,3. | 67,9. |
Свыше 500. | 1,7. | 32,1. | 100,0. | 100.0. |
Итого. | 100,0. | 100,0. | ; | ; |
По оси х будем откладывать кумулятивные итоги процента городов (графа 4), а по оси у — кумулятивные итоги процента численности населения (графа 5). На плоскости квадрата найдем точки, соответствующие каждой паре кумулятивных итогов, соединив которые, получим кривую Лоренца (рис. 2.6).
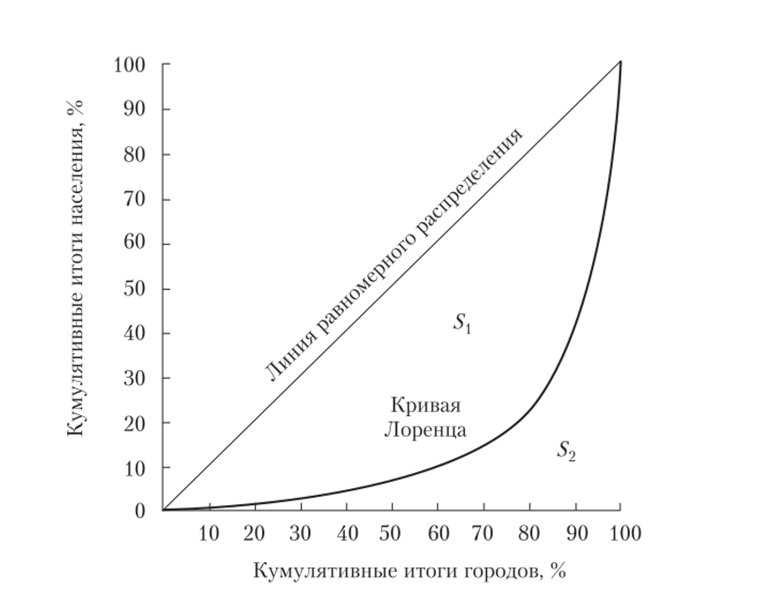
Рис. 2.6. Кривая Лоренца
Диагональ квадрата отображает равномерное распределение населения по определенным группам городов, г. е. одному проценту кумулятивных итогов городов соответствует один процент кумулятивных итогов населения. В действительности такое встречается крайне редко. Чем больше выпуклость кривой или чем больше она отклоняется от диагонали, тем выше концентрация изучаемого показателя или выше неравномерность распределения изучаемого признака. Построенная кривая Лоренца для нашей таблицы показывает неравномерное распределение численности населения по крупным городам. В одном квадрате можно построить несколько кривых Лоренца в разное время или по разным объектам, что позволит провести сравнительный анализ изучаемого показателя.
Степень неравномерности распределения измеряется коэффициентом Джини (G), геометрический смысл которого сводится к отношению площади (5j), заключенной между линией равномерного распределения (диагональю квадрата) и кривой Лоренца, к половине площади ква;
драта (5*! + 52), т. е. С = ——ЧгПлощадь + S2) = 0,5, тогда S{ = 0,5 — 52,.
+^2.
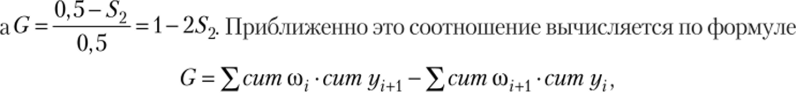
где сит со, — кумулятивные доли единиц распределения; сит г/, — кумулятивные доли суммарного показателя. Если обозначить сит со, через pvа сит у{ — через qv то получим G =? Рйм ~ X РмЧ-
Вычислим коэффициент Джини по данным табл. 2.6:

Заметим, что в расчетах можно пользоваться не кумулятивными долями, а процентами, и в этом случае результат вычисления необходимо разделить на 10 000.
Коэффициент Джини всегда больше нуля и меньше единицы. Чем ближе коэффициент Джини к единице, тем выше неравенство в распределении суммарного показателя; чем ближе этот показатель к нулю, тем выше равенство в распределении суммарного показателя.