Тестовая задача — распознавание символов

Символы в антигенах центрировались путём совмещения центра масс с геометрическим центром области (это не является особым упрощением в пользу ИИС, так как эквивалентно модифицированному правилу вычисления расстояния Антиген-Антитело, при котором центрируется массив антитела). Задача осложнялась тем, что каждый символ подвергался случайному масштабированию от 90 до 110 процентов по линейным… Читать ещё >
Тестовая задача — распознавание символов (реферат, курсовая, диплом, контрольная)
В качестве тестовой задачи было использовано распознавание цифр от 0 до 9.
Символы в антигенах центрировались путём совмещения центра масс с геометрическим центром области (это не является особым упрощением в пользу ИИС, так как эквивалентно модифицированному правилу вычисления расстояния Антиген-Антитело, при котором центрируется массив антитела). Задача осложнялась тем, что каждый символ подвергался случайному масштабированию от 90 до 110 процентов по линейным размерам, и случайному повороту в пределах ±15 градусов. В отличии от «игрушечной» задачи по распознаванию [De Castro et al., 2000], в которой каждому классу соответствует один образец данных, для успешного распознавания системе необходимо выполнить обобщение основываясь на различных образцах символов с разными масштабами и поворотами. Ниже приводится график точности классификации, полученный в результате пробного запуска системы. иммунный символ текст обучение Табл. 2.
Антигены. | Цифры от 0 до 9 в виде двоичных массивов размером 15*15. | |
Антитела. | Двоичные массивы размером 15*15. | |
Инициализация. | Пустые массивы, пороги связывания — расстояния до случайных антигенов. | |
Мутация. | Инверсия 8ми случайных точек, домножение порога связывания на случайное число из диапазона [0.8.1.2]. | |
Скрещивание. | равномерное скрещивание (uniform crossover). | |
Мутация/ Скрещивание. | 50%/50%. | |
Селекция. | Пропорционально приспособленности. | |
Связывание. | Расстояние по Хэммингу, локальные пороги связывания. | |
Размер популяции. | ||
Скорость обучения. | 20%, 5% после 1000 поколений. | |
Предъявляемых антигенов за поколение. | 300, 1000 после 1000 поколений (новый случайный набор каждое поколение). | |
Поколений. | ||
Время работы. | 20 минут / Celeron 1200 Mhz. | |
Через 1000 поколений обучение было продолжено с уменьшенной скоростью обучения и увеличенным количеством предъявляемых антигенов в течение ещё 1000 поколений. Такое изменение параметров было произведено с целью экономии времени в начале и уменьшения случайных флуктуаций состояния системы в конце — замена большого количества антител за поколение и маленькая статистика отрицательно влияют на стабильность. Финальная точность классификации составила 99%.
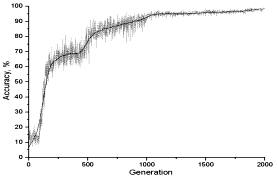
Рис. 2. Обучение системы — распознавание символов (серый — мгновенные, чёрный — средние значения).
По результатам запуска можно сделать следующие замечания:
Рост точности классификации обеспечивается лишь в среднем, из-за случайного характера системы мгновенные значения точности могут сильно флуктуировать.
Системе удалось произвести обобщение различных образцов одного класса с разными масштабами и поворотами. Аналогично может быть выработана инвариантность распознавания к искажениям, шуму, изменению шрифта.
Не смотря на то, что двоичные массивы антител были инициализированы цветом фона (что означает, что в пространстве параметров они находились далеко от областей, занимаемых классами), обучение привело к созданию эффективных антител, хотя системе потребовалось определённое время (первые 100 поколений) для создания полезных битовых массивов.
Не смотря на то, что в системе нигде напрямую не используются данные об антигенах (например, в отличие от CLONALG [De Castro et al., 2000], при репликации не отдаётся предпочтение антителам, близким к каким-либо антигенам), система смогла произвести эффективные антитела, что говорит о более тонком поведении, чем стохастический направленный поиск.
Был выработан оригинальный способ распознавания: антитела визуально не похожи на распознаваемые символы и имеют хаотический вид (Рис. 3). Даже после усреднения массивов антител одного класса, узнать символы можно лишь с трудом (Рис. 4).
Результат не является тривиальным: если создать случайную выборку из 300 образцов распознаваемых символов и осуществлять распознавание по классу ближайшего соседа, точность классификации оказывается меньше (98%).
Распределённая память: классификация имеет коллективный характер, поэтому удаление отдельных антител не влияет на функционирование системы в целом. Неплохая точность обеспечивалась даже после удаления 80% случайных антител (Рис. 5).

Рис. 3. Пример распознавания символа. Справа от антигена приведено несколько связанных антител.
Всего связано 17 антител с правильным классом, 3 с неправильным. Большинством голосов антиген классифицируется как цифра 6.

Рис. 4. Усреднённые массивы антител одного класса.
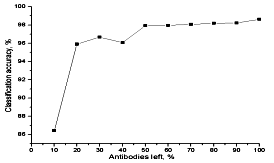
Рис. 5. Устойчивость к удалению антител.